A future where catalog search gets tuned to your domain, not forced into vendor defaults.
The vision is an agentic catalog-search tuning platform for mid-market teams that do not have spare search, product, and ML bandwidth. You bring a catalog and real customer queries. Agents help benchmark, diagnose failures, tune the stack, and hand back a search endpoint that fits the domain.
Who this is for
Mid-market catalog businesses and non-technical founders losing search-to-conversion without a dedicated search team.
Why now
Embeddings, rerankers, and LLM agents moved the technical baseline. The bottleneck is engineering bandwidth, not model capability.
Reference proof
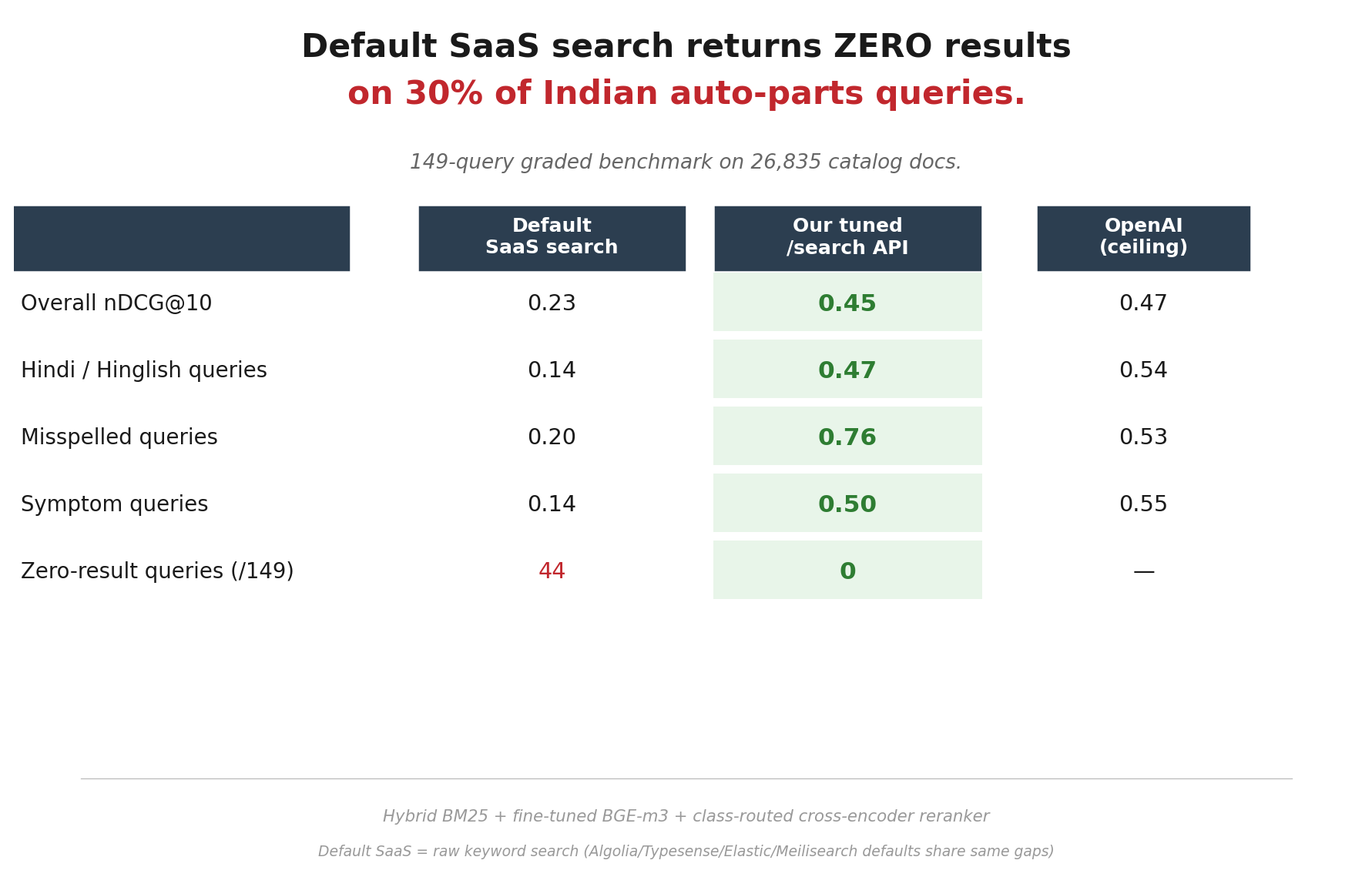
Indian auto parts was the first proving ground because it is one of the worst-behaved search surfaces anywhere.
Product direction
The auto-parts endpoint is the wedge. The real product is the repeatable tuning system behind it.